

성서는 하나의 책이지만 수천 년의 세월의 역사를 담고 있습니다. 그리고 한 사람이 한 자리에서 쓴 것이 아니라 여러 사람들의 손길을 거치고 오랜 시간에 걸쳐서 텍스트로 정착된 것이기 때문에 매우 다양한 언어적인 특징을 나타내고 있습니다. 그래서 성서의 역사를 밝혀내고자 하는 학자들은 언어적인 특징에 상당한 관심을 기울이고 있습니다. 왜냐하면 시대의 흐름에 따라 언어가 변화하는 특징을 가지고 있기 때문에 언어적인 특징을 잘 구분하면 해당 본문이 쓰여진 시대를 어느 정도 유추할 수 있기 때문에 그렇습니다.
본 포스팅은 구문 정보가 포함되어 있는 성서 데이터 베이스(Text-Fabric)와 다양한 통계 수치를 산출할 수 있는 통계 프로그램인 R을 이용하여 간단하게 성서 히브리어 문체 분석을 해 보도록 하겠습니다. 본 포스팅에서 사용한 데이터베이스와 데이터를 산출하기 위한 코드는 아래를 참조해 주십시오.
•
Text-Fabric: 어형, 구문 등과 같은 다양한 성서 히브리어 정보가 수록되어 있는 오픈 데이터베이스(https://github.com/ETCBC/text-fabric/wiki)
•
Text-Fabric에서 필요한 데이터를 뽑아서 csv 포맷으로 저장해 주는 Python Code 소스 (https://github.com/kungsik/text_fabric_sample/blob/master/tf_for_machine_learning_1.ipynb)
•
데이터를 뽑고 R 코드 소스를 작성하는 방식에 대해서는 나중에 동영상으로 따로 업로드를 하려고 합니다. 아무튼 제가 간단한 성서 문체 분석을 하기 위해 수행한 절차는 아래와 같습니다.
•
샘플 텍스트 선정: 샘플 텍스트는 텍스트의 시대 구분에 있어서 학자들의 이견이 거의 없는 것으로 선정을 해야 합니다. 저는 포로기 이전의 본문으로 사무엘서를 택하였고, 포로기 이후의 본문으로 역대기서를 택하였습니다.
•
시험 텍스트 선정: 샘플 텍스트 분석을 통해 어느 정도 특징을 구별해 낼 수 있으면 이 데이터를 토대로 시대를 추측할 대상인 텍스트를 선정해야 합니다. 저는 레위기와 에스더를 선정했습니다. 이 책들이 포로기 이전의 언어에 가까운지, 포로기 이후의 언어에 가까운지 혹은 과도기적인 특징을 보이는 지를 살펴볼 것입니다.
•
분류 기준 선정: 어느 특징에 따라 텍스트를 분류할 것인지를 결정해야 합니다. 정확한 분석을 위해서는 다양한 언어적인 특징들을 적용해야겠지만, 저는 프랑크 폴락(Frank Polak)이 제시한 여러 기준 가운데 명사절 비율[1]과 아비 후르비츠(Avi Hurwitz)가 제시한 여러 기준 가운데 אל과 על 전치사 사용 비율[2] 등을 기준으로 텍스트의 특징을 파악해 볼 것입니다.
일단 샘플 텍스트와 시험 텍스트의 데이터를 뽑아서 각각의 책들에서 나타나는 절 형태의 비율을 산출했고, 시각적으로 확인이 쉽도록 아래와 같이 그래프로 표현했습니다.
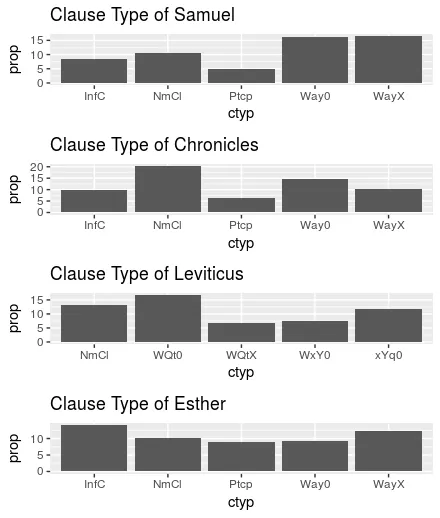
위 그래프는 책 별로 가장 많이 사용된 상위 5개의 절 유형을 분석하고 있는 그래프입니다. 각 지표는 아래와 같습니다.
•
InfC: 구문형 부정사 절
•
NmCl: 명사절
•
Ptcp: 분사절
•
Way0, WayX, WQtX: 봐브+동사로 이루어진 다양한 유형의 동사절
위 유형들 가운데 동사절을 제외한 구문형 부정사 절, 명사절, 분사절 등은 모두 명사적인 요소로 이루어진 절이라고 볼 수 있습니다. 위의 지표를 살펴보면 역대기에서 명사절의 비율이 상당히 높게 나타나는 것을 발견할 수 있습니다. 반면 사무엘서는 동사절의 비율이 매우 높습니다. 즉 후기의 책일수록 명사절의 비율이 높다는 폴락의 이론을 어느 정도 뒷받침해주는 지표라고 볼 수 있습니다.
그리고 레위기와 에스더서의 경우를 보면 레위기는 명사절보다는 동사절의 비율이 크게 나타나는 것을 볼 수 있습니다. 명사절의 비율만 놓고 본다면 레위기는 포로 후기의 문체를 보이고 있지는 않은 것 같습니다. 반면 에스더서는 명사절 비율이 높게 나타나는데 이는 에스더서가 포로 후기의 문체를 전형적으로 나타내 보이고 있는 것 같습니다. 좀 더 그 차이를 확실히 하기 위해 각 책의 명사절 요소들의 비율을 모두 합산하여 점 그래프로 아래와 같이 만들어 보았습니다.
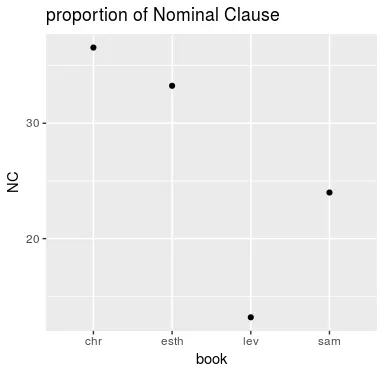
위에서 유추한대로 역대기서와 에스더서, 그리고 레위기와 사무엘서과 명확하게 구별됨을 볼 수 있습니다. 레위기는 사무엘서보다도 명사문장의 비율이 상당히 낮게 나오는 것을 볼 수 있는데 편의 상 상위 5개의 문체들만 가지고 통계를 낸 것이라 실제로 레위기의 명사문장 비율은 이보다는 더 높게 나올 수 있습니다. 아무튼 레위기는 사무엘서에 보다 가까운 문체 특징을 보이고 있습니다.
다음으로 전치사의 사용 스타일을 보도록 하겠습니다. 위에서 했던 대로 우선 각 책에서 나타나는 전치사 사용 비율을 아래와 같이 그래프로 표현해 보았습니다.
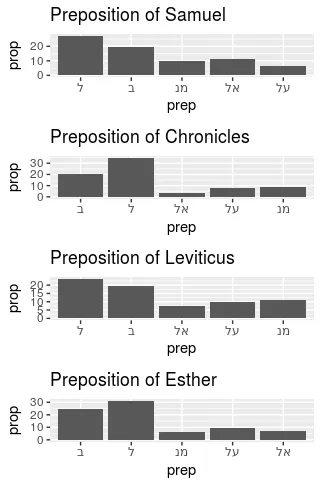
한 눈에 봐도 ל 전치사가 가장 많이 사용되고 있는 전치사임을 볼 수 있습니다. 각각 전치사의 사용 비율을 살펴보면 그렇게 의미 있는 데이터는 눈에 띄지 않습니다. 그런데 앞서 제가 언급했듯이 여기서 중요한 것은 אל과 על의 사용 비율입니다. 사무엘서는 אל이 על보다 빈번하게 사용되고 있는 것을 볼 수 있습니다. 그런데 역대기에서는 완전히 반대입니다. על이 אל보다 훨씬 많은 비율로 사용되고 있습니다. 레위기와 에스더에서도 על이 많이는 아니지만 보다 더 많이 사용되고 있는 것 같습니다.
이 데이터를 על의 사용 수 / אל의 사용 수 공식을 이용하여 사용 비율 값을 구한 뒤 아래와 같이 점 그래프로 표현해 보았습니다. 값이 크면 클 수록 על의 사용 비율이 보다 높다는 의미입니다.
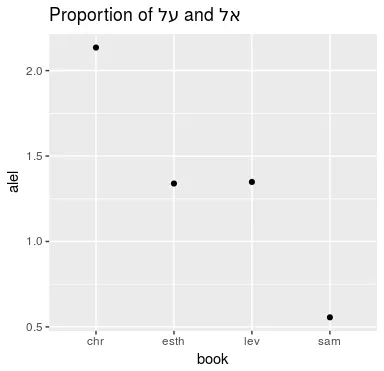
매우 재미있는 결과가 나왔습니다. 위의 그래프에서 볼 수 있듯이 역대와 사무엘서의 특징이 명확하게 구분됩니다. 그런데 에스더서와 레위기는 거의 중간 값을 가지고 있는 것을 볼 수 있습니다. 전치사의 특징 만으로 본다면 에스더서와 레위기는 과도기적인 언어 특징을 보이고 있다고 볼 수 있습니다.
위의 명사 문장 데이터와 전치사 사용 비율 데이터를 통합하여 생각해 본다면 에스더와 레위기는 기본적으로 포로기 이전에서 포로기 이전 말이나 포로기로 넘어가는 시대의 과도기적인 언어 특징을 보이고 있다고 볼 수 있습니다. 물론 에스더서는 내용상으로 볼 때 포로기 이후의 책임에는 틀림이 없습니다. 그런데 저자는 의식적으로 어느 정도 포로기 이전의 성서 히브리어를 작성하려고 애를 썼는지도 모르겠습니다. 그리고 레위기는 그 시대 구분에 있어 학자들의 논쟁이 매우 뜨거운 책입니다. 섣불리 단언할 수는 없지만 위의 데이터를 통해 볼 때 레위기는 아주 늦은 시대는 아니고 포로기 이전 후기 정도의 과도기적 특징을 보이는 것이 아닌가 하는 생각이 듭니다. 정리하면 아래와 같습니다.
사무엘서(포로기 이전) -> 레위기(포로기 이전 후기) -> 에스더(포로기 이후 전기) -> 역대기(포로기 이후 후기)
본 포스팅은 매우 일부분으로 성서의 문체를 간단하게 유추한 것에 지나지 않습니다. 그러나 앞으로 이러한 통계 툴 등을 통해 성서 문체 연구를 지속해 나갈 예정이고, 성서 문체를 분석할 수 있는 툴도 앞으로 선보일 예정입니다.
[1] 명사절 비율이 높을수록 구어체보다는 문어체에 가까우며 이는 포로 후기 서기관 전통을 반영하는 것이다.
[2] 포로 후기 문헌으로 갈수록 아람어의 영향으로 אל 보다는 על을 선호하는 경향이 강하다.